I’ve spent a bewildering number of evenings trying to get my head around how I’ll be able to wire up storage for Kubernetes in a real world scenario. Out of the box, Kubernetes comes with a hole heap of options to back PersistantVolumes (from here on out known as PVs). There are two immediate problems:
- Using persistant storage in Kubernetes based setups is an antipattern. Block devices are not ‘cloudy’. Your standard 12 factor app shuns the idea of ‘a disk’. With good reason. Traditional storage doesn’t fit in well with the ‘as a service’ model that you need when you’re spinning up containers like a magician with Dover over-population problem. As result the options for traditional storage types of quite limited.
- The PV types available are all biased towards the newer generation of clustered storage abstractions (and cloud provided options) – the new sexiness of GFS and Ceph. I’m riding a wave of change when contemplating a Kubernetes based deployment, and I’m trying to reduce the number of scary new things that need to go in to support this.
Enter NFS
So, looking at the ‘out of the box’ options, you get an NFS based PV. There’s quite a nice example of this up on github – [ https://github.com/kubernetes/examples/tree/master/staging/volumes/nfs]. Translating this into my home lab setup, I can set up a PV like this without too much trouble:
[root@kubemaster01 kube]# cat simple_nfs_pv.yml apiVersion: v1 kind: PersistentVolume metadata: name: nfs spec: capacity: storage: 1Mi accessModes: - ReadWriteMany nfs: server: freenas.home path: "/mnt/vol01/kubenfs01/test"
Breaking this down:
- Create a PV with the name of ‘nfs’
- Allocate 1Mib
- Set the access mode so that many nodes can mount up this PV
- Point it at my freenas server
A small sidebar on accessModes
The access modes govern the cardinality of PV to node:
- ReadWriteOnce – the volume can be mounted as read-write by a single node
- ReadOnlyMany – the volume can be mounted read-only by many nodes
- ReadWriteMany – the volume can be mounted as read-write by many nodes
In the CLI, the access modes are abbreviated to:
- RWO – ReadWriteOnce
- ROX – ReadOnlyMany
- RWX – ReadWriteMany
So if you apply that:
kubectl apply -f simple_nfs_pv.yml
You should get a new StorageClass:
[root@kubemaster01 ~]# kubectl get storageclass
NAME PROVISIONER AGE
local-storage kubernetes.io/no-provisioner 6d23h
That is all very well and good, however, but that particular solution doesn’t scale for 2 reasons:
- Every single application (or Pod in Kubernetes parlance) might need a PV. So you’ll land up having to constantly dish out PV’s to as applications come up – which is a frequent occurrence in Kubernetes – by design.
- When you have applications that need their own storage i.e. ReadWriteOnce accessModes (e.g. Kafka or Zookeeper), the PV’s given out to those Pods need to be associated with those specific instances. I.e. If the kafka cluster is scaled out it needs MORE storage – it can’t simply use the PV that’s been given to an existing Pod. If a kafka pod dies, and a new one is created, unless it’s pod that has the same identity as the old one (getting into the idea of StatefulSets here – basically the ‘hostname’ the same), then it can re-use the previously allocated storage. So you need a way of quickly allocating new portions of storage that aren’t shared by anything else.
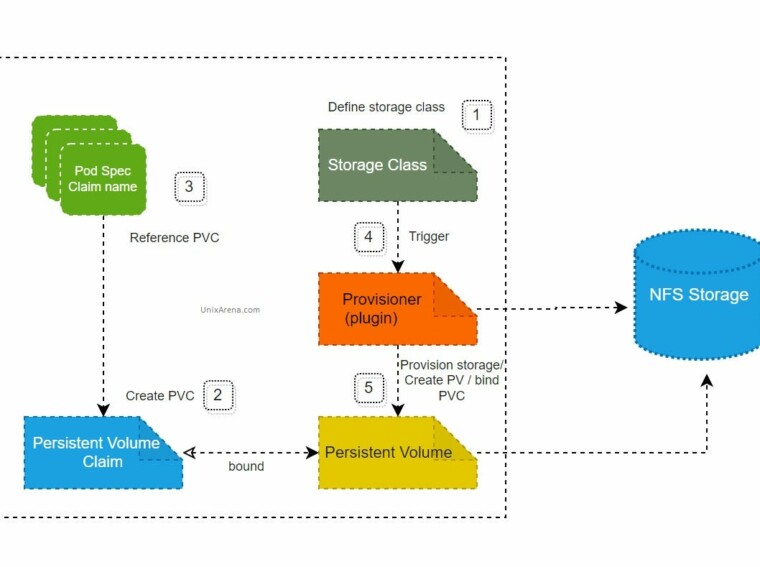
Persistent Volume Claims and Storage classes
This is where Persistent Volume Claims and Storage Classes come in. Instead of trying to use an explicit volume, a Deployment can ask for storage (a claim) from a particular type of storage (a StorageClass).
The example of a StorageClass in the Kubernetes documentation is a good one: You have some ‘fast as hot snot’ ssd’s and some slightly slower spinning rust. You’d create two storage classes – one ‘Fast’ and one ‘Slow’. Your Deployment configuration can then decide if it needs the Fast storage or the Slow storage (or both?)
So the relationship here is simple: Persistence Volume Claims (PVC’s from here on out) ask StorageClasses for Volumes (in this case Persistent Volumes) that are in turn used by Pods.
+--------------+ +------------+ +----------------> | | | | | | | | |
+-----+----+ | PVC +--> | PV |
| | | | | |
| Storage | | | | |
| Class | +--------------+ +------------+
| | +--------------+ +------------+
| +-----------> | | | |
| | | | | |
+-----+----+ | PVC +--> | PV | | | | | | | | | | | | +--------------+ +------------+ | +--------------+ +------------+ | | | | | +----------------> | | | | | PVC +--> | PV | | | | | | | | | +--------------+ +------------+
So…
So where does that leave the NFS conversation? Storage classes are frustratingly simple things – there’s no way to specify an NFS server host and path in any of the examples online.
A lot of googling shows that there are two types of NFS use case that come up frequently:
This one comes up very frequently, and usually involves exposing a storage volume provisioned by a cloud provider as an NFS share internally to the Kubernetes cluster. This is because of a limitation on the cloud storage options – they only support certain types of accessModes e.g. ReadWriteOnce. So you want a shared bit of storage that many of your nodes and pods can read and write to, then you need to do this ‘conversion’. It is, however not what I’m looking for. I already have an NFS server. I don’t want another one.
2. Exposing NFS client functionality as a Storage Class
After much rummaging about, reading, and failed trials, this is the language that describes what we’re looking for. The light came when when reading this article. And amazingly there is actually a pre-baked solution ready and waiting for us over at helm: [https://github.com/helm/charts/tree/master/stable/nfs-client-provisioner]
With a simple helm command, we can conjure up the StorageClass that we’ve been missing:
helm install stable/nfs-client-provisioner --set nfs.server=freenas.home --set nfs.path=/mnt/vol01/kubenfs01 --name nfs-client
Now, I’m still a bit of a noob with all this. I can see that it’s deploying a new Deployment, with a special container that is doing some magic. It is mounting the NFS volume that I’ve set on the node, and presenting that to the container. The container is obviously then in charge of dishing out subvolumes from there.
There is of course a small gotcha…
Any kube node that presents this storage needs to mount up the nfs share that you specify in the helm command. So it needs to have the necessary packages installed on relevant nodes. E.g. as per this article https://www.howtoforge.com/nfs-server-and-client-on-centos-7
Unleash the Kafka
There is a StorageClass deployed with that matches the name of the helm chart (nfs-client), and this allows me to very simply wire up some clients.
e.g Using the kafka Helm chart:
helm install --name kafka-cluster --set replicas=5 --set persistence.storageClass=nfs-client incubator/kafka
and the elastic search helm chart:
helm install --name elasticsearch --set master.persistence.storageClass=nfs-client --set client.replicas=3 --set data.replicas=3 stable/elasticsearch
The Jenkins Helm chart proved a little more complicated, as it wanted a PV not a PVC, so I had to wire up this:
[root@kubemaster01 kube]# cat jenkins_pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata: name: jenkins
spec: accessModes: - ReadWriteOnce storageClassName: nfs-client resources: requests: storage: 10Gi
And then fire up the helm chart with
helm install --set Persistence.ExistingClaim=jenkins --name jenkins stable/jenkins
Conclusion
Two light bulb moments:
- StorageClass –> PVC – never forget that. If you get that right PV’s happen as a byproduct.
- Helm NFS-client-provisioner. Use it.